The Client
The client is a leading consulting firm that advises businesses across the world on topics such as business growth, sustainable change, crisis management and more. Based on years of expertise and rich history, the client has substantial data repositories that our client’s consultants use to validate their decisions and advice.
The Challenge
The client needed a database-agnostic standard data model that integrates data from multiple sources. The current bottlenecks included a lack of technical expertise and challenges in data availability due to privacy concerns.
Expressly, pharmaceutical companies have limited analytics components across their several functions and business units. Data lakes within these units have individual structures, formats, and contents. Different groups also have multiple integration processes.
Analytics components are re-written using limited configuration files by profiling, ingesting and extracting data. This disparity in the data model inhibited smooth data flow across units. Its collation in a non-standard format led to fragmented decision making.
The Solution
The technical experts at Excellarate helped the client build an aggregate data model that receives its data from multiple sources. The team then built a descriptive analytics pipeline using this model.
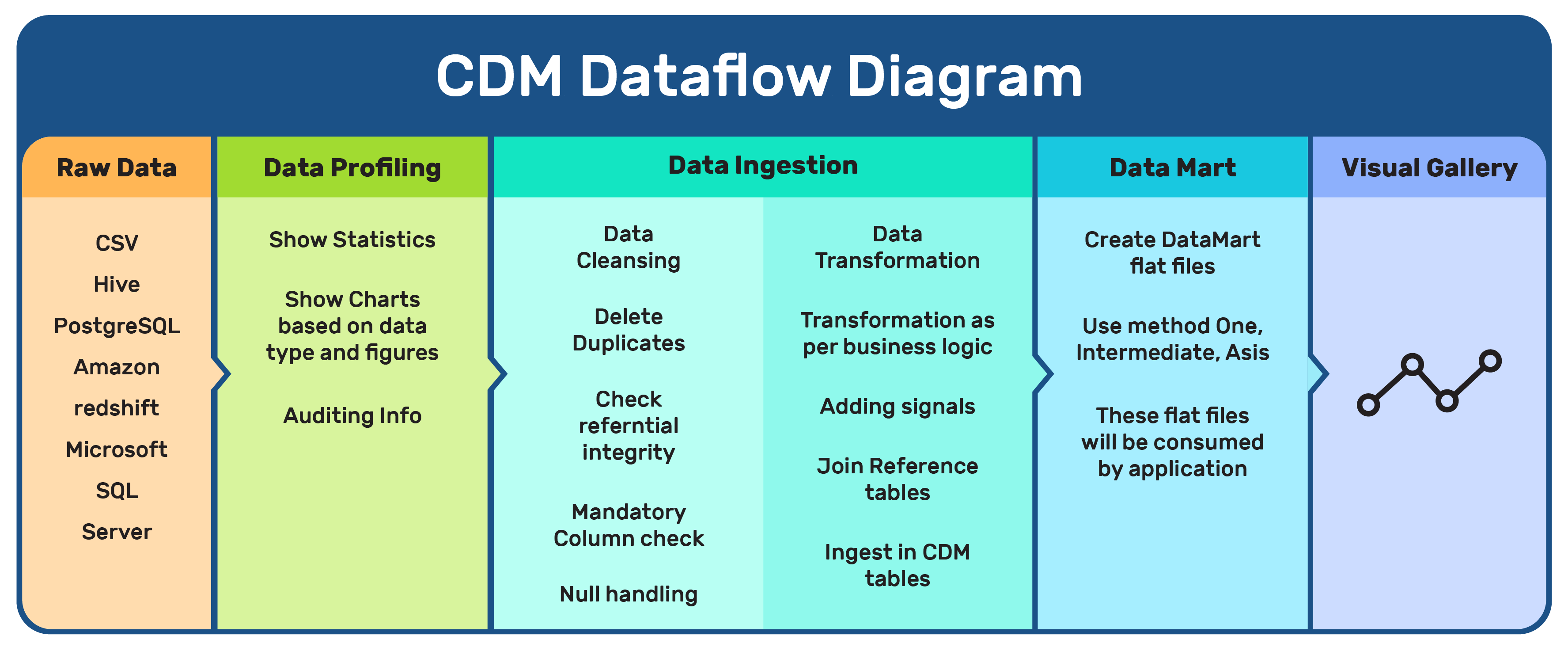
The Excellarate team helped the client simplify the process so that the business users could specify the data pipeline instead of technical experts. This meant the data needed to be processed from its raw format to standardized and easy to understand.
The Outcome
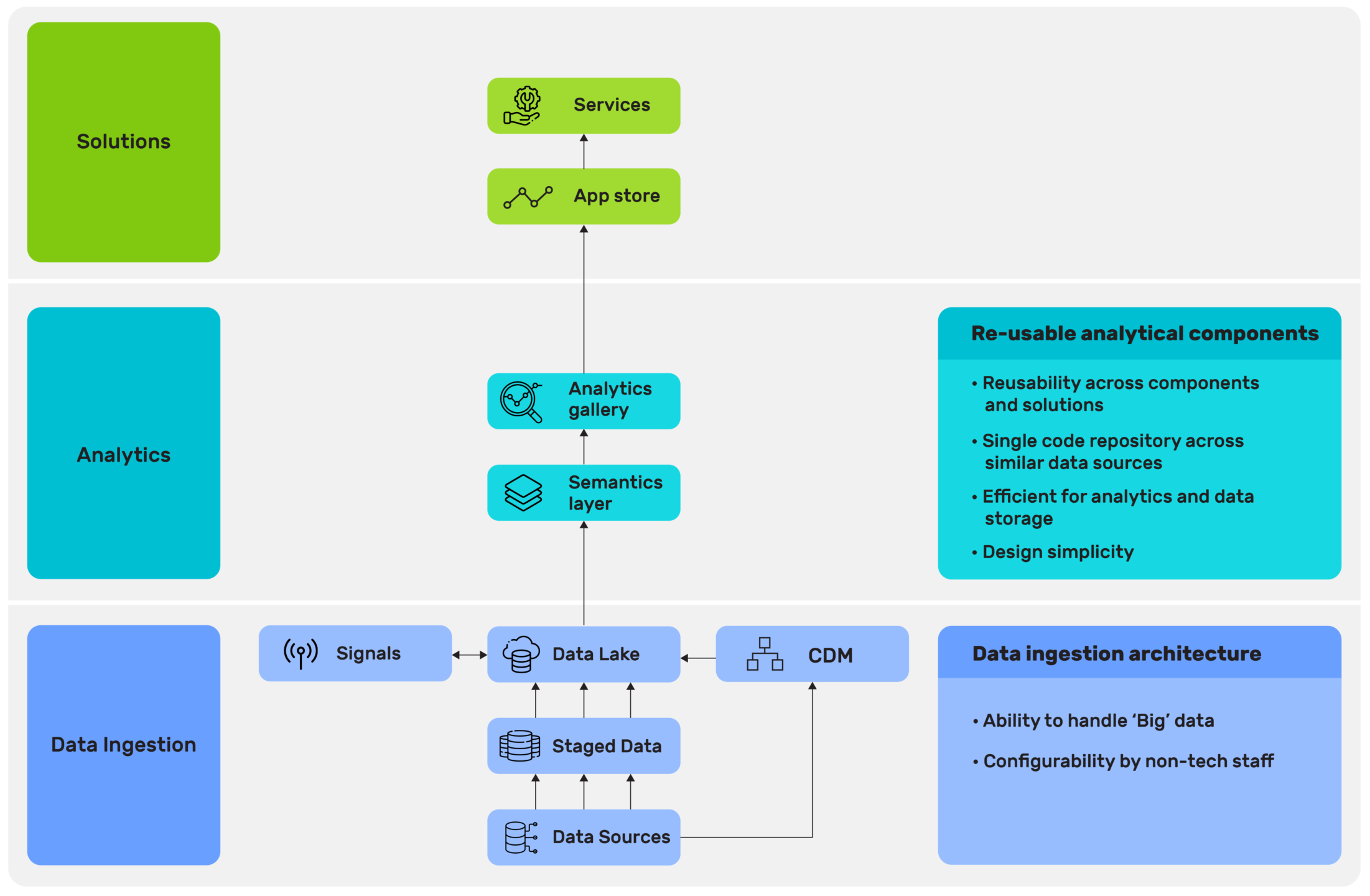
Since the data is now standardized from its original raw format, the underlying model now uses reusable analytical components. This reuse eliminates duplication of efforts to develop the same analytical modules in different units. This vastly reduces duplicate development effort and time and helps business users get the correct data for analysis exactly when they need it thereby increasing their productivity and effectiveness
A standard data workflow model eliminates the application development time spent on setup through data process standardization. In addition, the team’s configurable ETL solution using Python is database agnostic, enabling future scalability and integration with other solutions as the need be.