General Architecture for Text Engineering or simply GATE is a Java suite of open-source tools used worldwide by scientists, companies, teachers, and students for many Natural Language Processing (NLP) tasks, including information extraction.
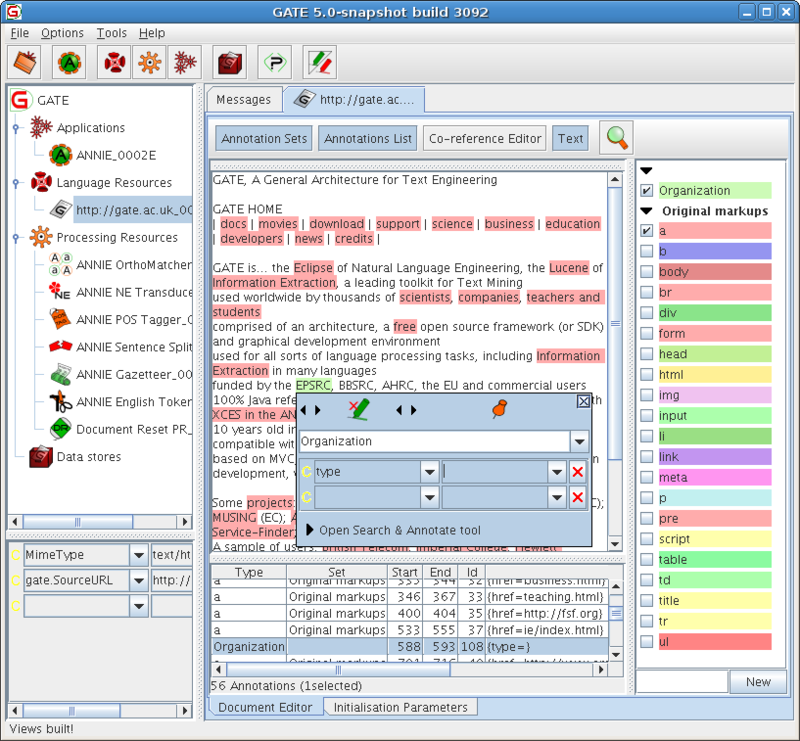
Source: https://en.wikipedia.org/wiki/General_Architecture_for_Text_Engineering
Recently we started work on a document processing engine using GATE’s NLP Library. The product was meant to allow its user to process data in documents available in diverse formats. But we hit a snag early. We realized that GATE is single threaded, meaning it will only perform tasks serially. And after processing a few documents, GATE service needed to be restarted. It also failed when processing documents that had errors or had special characters. We had to find a remedy and quick.
Microservices to the rescue
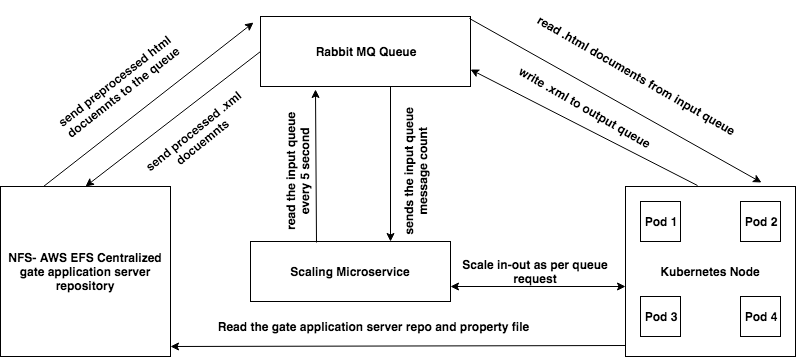
After evaluating a few alternatives, we had a winner in Microservices. Using Spring framework to develop Microservices and Kubernetes orchestration, we were able to successfully build the engine. We Dockerized all Microservices (GATE and scaling). We then created a Network File System (NFS) on Amazon (AWS EFS) and mapped the shared GATE folder across all pods. It stays in ‘listen’ mode to the input queue in order for it to process the document timely. Once processed, it writes the data into EFS output folder. Later, the output queue is read by the web application for further processing.
Scaling Microservices
To be able to scale in and scale out Kubernetes nodes and pods, there is a configuration that can be defined in Microservices property file. We configured it to listen to the input queue every five seconds. For instance, let’s say your input queue request exceeds 100 messages. In order to scale Microservices using Kubernetes API, we have to scale out the existing node count and launch the pods in order for us to process the input queue traffic. When there are few messages in the input queue, we scale in the Kubernetes nodes and pods.
Retrospective
Now a look back at some of the important measures we took while solving this issue. We started with observing memory and CPU usage patterns for GATE server. Close monitoring helped us identify the inflection point at which the server hangs.
We have used Prometheus and Grafana. Prometheus is a monitoring solution that gathers time-series based numerical data and can visualize the data on Grafana dashboard. Grafana being an open-source visualization tool for reporting purpose used here.
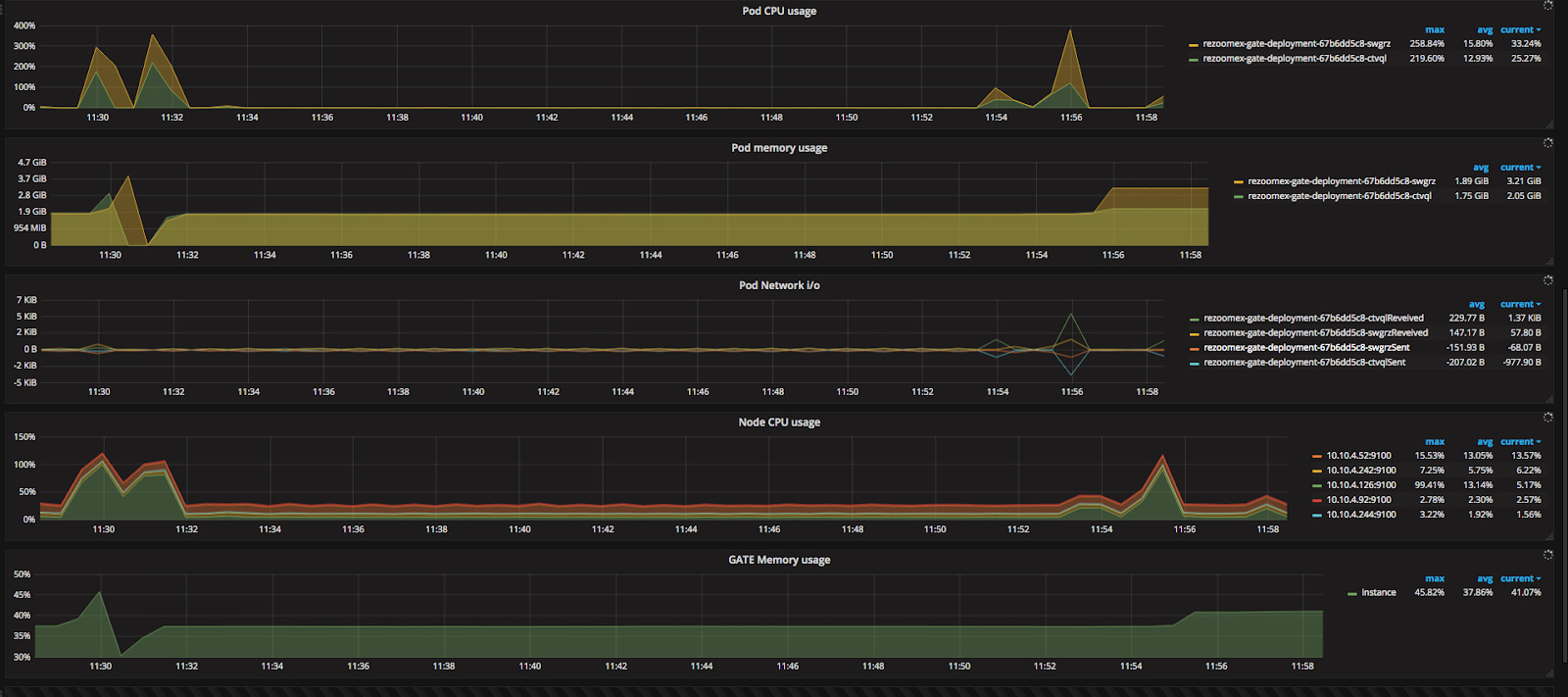
This meant, we could define the configuration memory allocation and limit for the pods. To ensure automatic restart of containers, we also defined liveness probes. It now checks the health of the application on a particular port and if it fails, it automatically restarts the pods.
livenessProbe:
httpGet:
path: /
port: 9090
initialDelaySeconds: 120
periodSeconds: 30
timeoutSeconds: 10
An extra safety net that we laid out was to configure GATE Microservices to restart the pod after processing a set number of documents. Not only that, if it is unable to process a document due to its contents, it will move that document to the delete / review queue after waiting for 60 seconds.
If you are planning to apply GATE’s NLP library to automate your business process, you may need an environment to avoid glitches and performance issues.


Ask us a question or talk to one of our experts. Email us or call us at +1.469.374.0500.